In this blog post, I would like to share my experience with Redis, including a made-up story about a team grappling with a system that uses Redis as a database. This story is based on actual events, drawing from my own experiences as a software engineer over the past decade. Although it may not be as well-written as The Phoenix Project (which I highly recommend reading), I hope you will find it both informative and entertaining. So, let’s blast off to a galaxy far, far away. Our story revolves around a public transport ticket management system.
The Star of the Show
In our intriguing realm of public transport ticket management, the imaginary system’s core task is straightforward: generating 40-character alphanumeric strings as transport tickets, which swiftly find their place in the Redis database. Our diligent system ensures ticket validity by checking their presence in the database and their activation status. Activation is a must, as tickets remain “active” for just one hour before they expire. Tickets have a one-year lifespan, after which they disappear. So, no point in stockpiling transport tickets for your future commutes!
A Place in the Cloud
The system is running on AWS ECS, powered by an AWS-managed Elasticache Redis database. We wanted to guarantee uninterrupted service, that’s why the database can boast a single primary node and two replicas. This infrastructure ensures seamless ticket issuance, verification, and activation, without any hiccups.
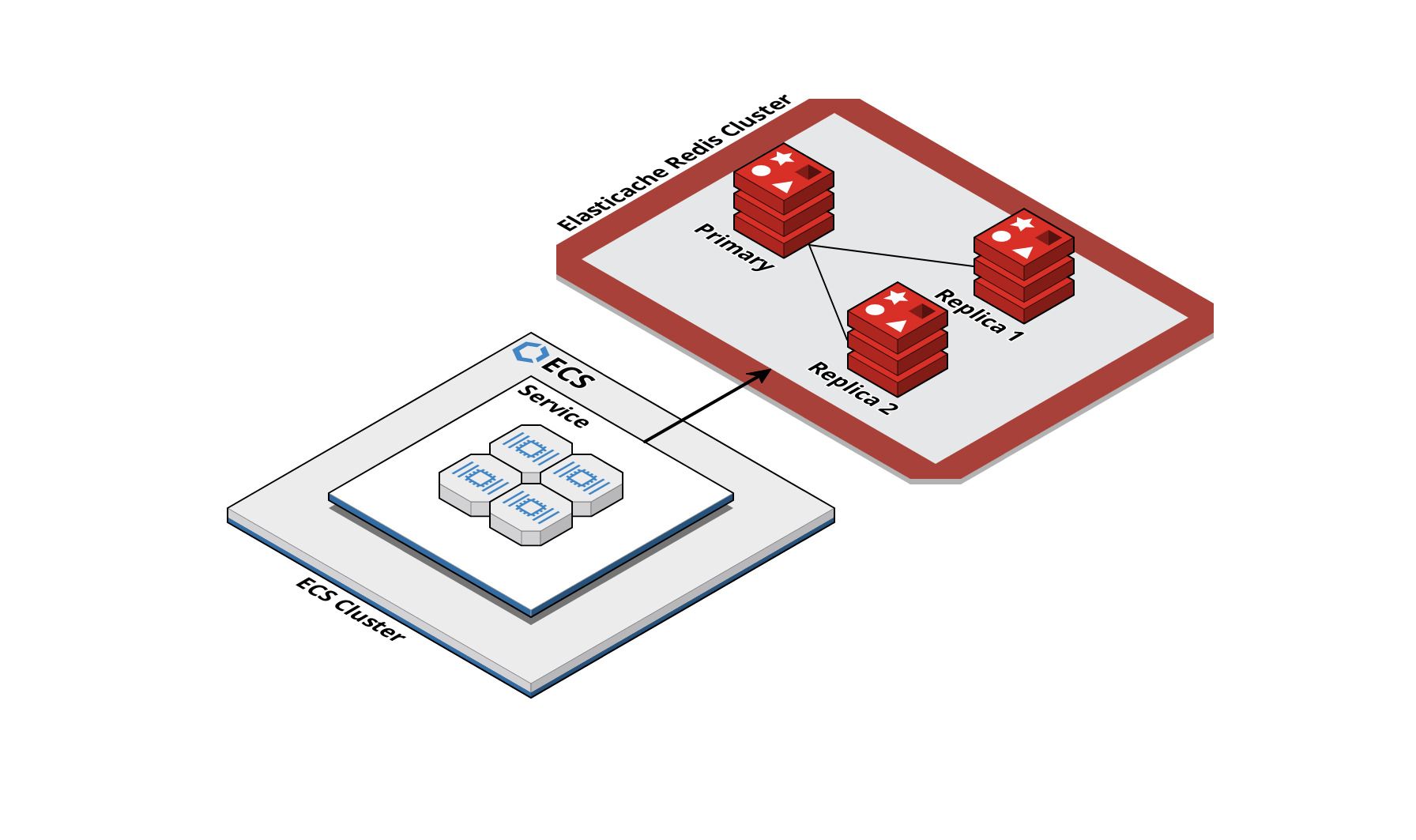
The Horror
In this far-off galaxy, the dev team was going about their daily business when they received a message from management: the transport ticket system was now their responsibility. The handover went smoothly, and for a year, the team didn’t need to make any significant changes to the system. It performed as expected, and life was good.
But one day, the team received complaints from some customers about issues with their tickets. After scouring through logs, traces, and metrics, they found no issues with the system. However, while investigating the issue, the team noticed something strange: the Redis database memory usage was at 100%. The team expanded the metrics view over a more extended period and found that it had been flat-lining at 100% for almost half a year!
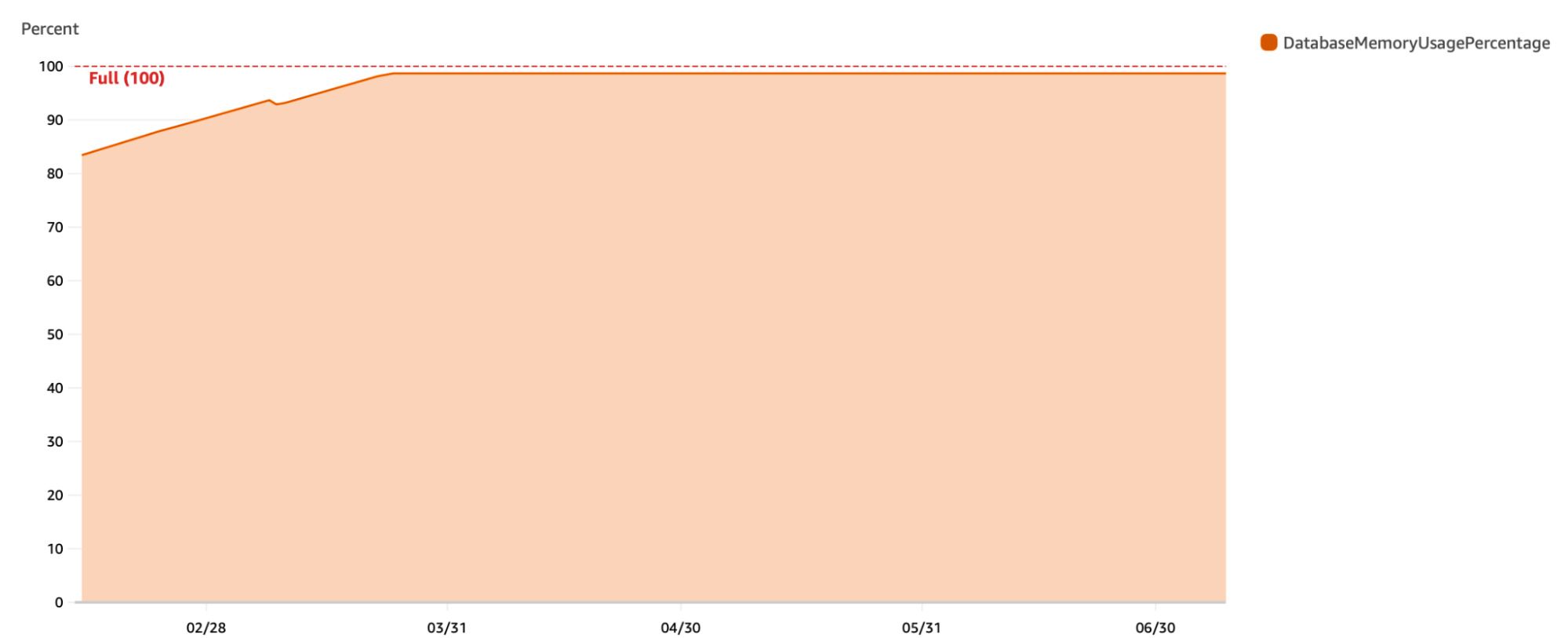
The realization was shocking – how had the system not crashed yet? The team knew they were in for a wild ride. The horror had just begun.
This is Fine, Right?
Clearly, since this 100% memory usage situation has been running for a long time and nobody complained, it is nothing to worry about, right? We took some time to investigate how Redis handles out-of-memory situations. Redis has multiple strategies for such situations.
The default one and the one that was used in our case was the volatile-lru strategy, which says: Removes least recently used keys with the expire field set to true. Now, what does “least recently used” mean, and what is an “expire field”?
Redis tracks the last access time for each of the fields. Not every operation in Redis updates the last access time. For example, with GET, SET, EXPIRE, PERSIST commands, the access time is updated, but not after commands like INCR, HSET.
Each item in Redis can have an expiration time (TTL). Running EXPIRE mykey 60 command would remove mykey after 60 seconds. You can also insert a new item into Redis and set expiration time for it immediately like this: SETEX mykey 10 “Hello”. This inserts a new key mykey, with the value “Hello” and automatically removes it after 10 seconds.
So, back to the volatile-lru strategy. It only removes items with a time-to-live (TTL) set, and from those items, it removes the least recently used ones first. For our ticket system, this is perfect! All our tickets in Redis have a TTL, so they’re automatically removed when the database is full. And only the oldest tickets are removed, which are most likely already been used or are going to expire soon anyway. This explains why nobody noticed the issue for almost half a year.
But wait a minute. If the database is full, doesn’t that mean there’s something wrong with our system? As much as we hate to admit it, yes, there probably is. And that’s where the fun begins.
No, this is not Fine!
We always set a TTL for every item we put on Redis. However, after noticing an unexpected database usage pattern, we decided to double-check that by connecting to the Redis database on the staging environment and running the info command. This command provided us with a lot of information about the database, but the section we were most interested in was Keyspace. This is what we saw:
> info
# Keyspace
db0:keys=49124,expires=653,avg_ttl=6225218844Unfortunately, the Keyspace section showed that out of the 49124 items in the staging environment, only 653 had a TTL. This was a red flag, as we always set a TTL for every item. We then checked production.
> info
# Keyspace
db0:keys=11057088,expires=241115,avg_ttl=5534176643In production, we noticed that out of approximately 11 million items, only around 240,000 (~2%) had a TTL, which was concerning.
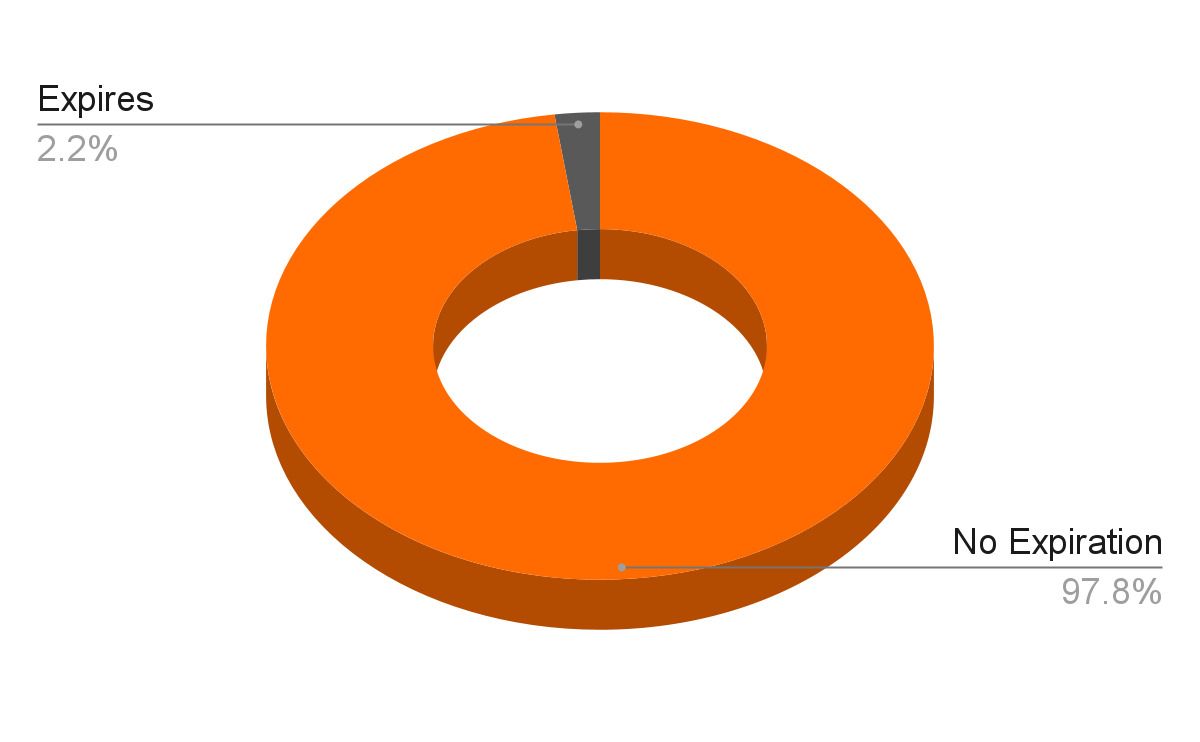
Our finding indicated that something was amiss with our ticket system, so we immediately began investigating the code for any potential bugs. After a thorough search, we discovered that all items were being inserted without a TTL due to a bug in the code. I won’t reveal the nature of the bug just now to keep some intrigue.
Searching for the bug, we checked the same metrics after 4 hours:
> info
# Keyspace
db0:keys=11058653,expires=229004,avg_ttl=5534315661The number of items with a TTL is decreasing… At this point, we were getting into a mild panic state. This meant that we had quite a limited time frame to fix this. Why? Because of how Redis would react once there was nothing with a TTL to remove.
According to Redis docs, this is what happens when it runs out of memory and has nothing to remove according to the eviction policy:
If Redis can't remove keys according to the policy, or if the policy
is set to'noeviction', Redis will start to reply with errors to commands
that would use more memory, like SET, LPUSH, and so on, and will
continue to reply to read-only commands like GET.With the passage of time, as all items with TTL are evicted, Redis would eventually return an error, bringing our entire system to a grinding halt. This would effectively bring ticket sales to a standstill, leaving us with a sea of irate customers unable to purchase their tickets and get to work on time. The mere thought of such a scenario was enough to send shivers down our spines, not to mention the wrath of our management.
As we watched the number of items with TTL gradually decrease, our concern grew. We knew we had a limited window of opportunity to fix the issue before it caused a major disaster.
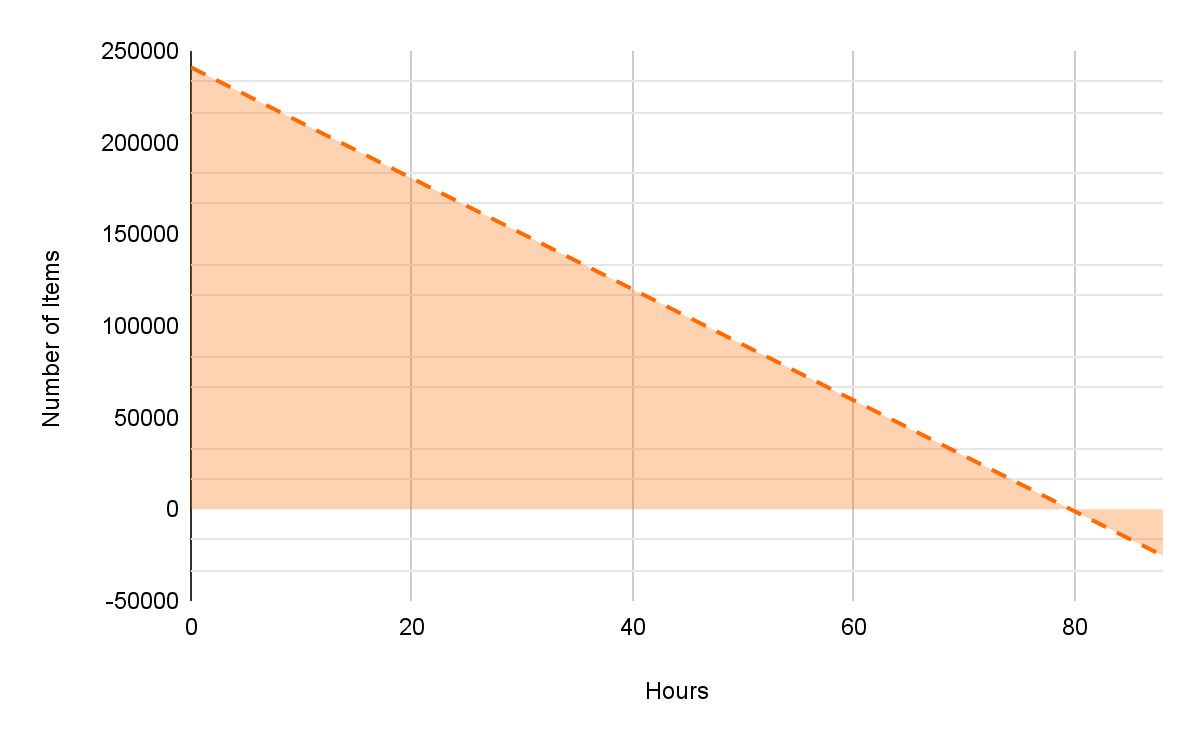
After crunching some numbers, we realized that we had burned through some 12111 items over a period of four hours. At that rate, we would be losing 72666 items per day. With 229004 items remaining, we had around 3 days left to fix the issue. However, this was the best-case scenario because our measurements were taken during a lull in ticket purchases. It was a Friday evening – with the upcoming weekend and peak ticket purchase times approaching, we probably had even less time than we had calculated. It was clear that we needed to act fast to implement a solution.
Making Everything OK
Our Options
As the team huddled together, we faced the daunting task of finding a solution to our Redis memory issues. Two options emerged from the brainstorming session:
- Option 1 – throw money at the problem by switching to Redis instances with more RAM.
- Option 2 – get our hands dirty and write a cleanup script to free up Redis memory.
As we were discussing this, these were the pros and cons towards of option 1:
Pros:
- This is the fastest fix.
Cons:
- There is a risk of Redis downtime while changing Redis instances to different ones.
- The risk that something goes wrong during the switch. Can we lose all data?
- We should have a backup at hand, but there was none set up previously.
Regarding option 2:
Pros:
- No changes to the infrastructure.
- No expected downtime.
Cons:
- Development effort is needed for the script.
- Risk of script misbehaving and corrupting the data.
Having limited time and a lot of unknowns, we did not want to take a big risk. That’s why we chose Option 2. We started writing the script and looking into database backups in case things went really wrong.
Backing up Redis
As we were choosing between the two options, we looked into how Redis does backups. It is quite an interesting process that I would like to share with you. First of all, we were worried that having Redis memory usage at 100% would mess up the backup process. As it turned out, it is quite safe to do Redis backup, even in conditions like this.
On AWS ECS, Redis node memory is divided into “Memory for data” and “Reserved memory,” with the latter set at 25% by default. This means that even if all memory is allocated for data, there’s still ample space reserved.
During the backup process, a separate Redis process is forked (due to Redis being a single-threaded application), resulting in two Redis processes running in tandem. While one process handles requests, the other executes the backup and buffers all changes in the reserved memory until completion. Once the backup is finished, all accumulated changes are flushed from reserved memory to data memory.
It is important to ensure everything goes smoothly. Therefore, it’s crucial not to exceed the 25% reserved memory limit within the duration of the backup process. There is comprehensive documentation on AWS for more details. Based on the rate at which we receive new data in Redis, we could not have filled up 25% of the database memory during the backup process. This means we could have safely utilized backups, but unfortunately, we were not aware of this on Friday evening.
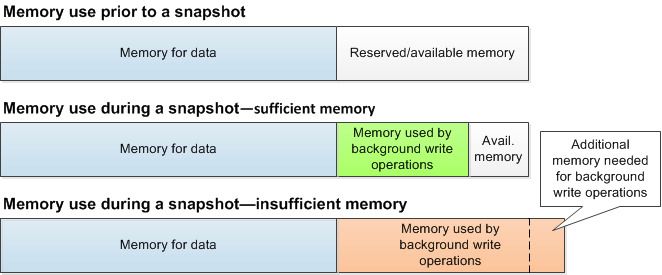
Source: https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/BestPractices.BGSAVE.html
The Script
The data key structure in Redis that we had was quite convenient for us. This is an example of some of the keys in the DB:
[CustomerToTicket]1384031470-488723-xhfj311
[CustomerToTicket]<timestamp>-<customer-id>-<random-suffix>So, an entry consists of a timestamp showing when the ticket was issued, a customer id, and a random suffix that we do not care about. That’s perfect! We could grab a timestamp and calculate the correct TTL from it and set it to each of the items. So, the basic algorithm goes like this:
- Do a full SCAN of a database.
- Set correct TTLs for each item with EXPIRE command.
- If it should not be expired yet – calculate the correct TTL and set it.
- If it should be expired by now – set a TTL of an hour.
Why set a TTL of an hour instead of immediately deleting it? This was a little trick that allowed us to have some time in case we noticed that the wrong items are marked for deletion.
So, we ran the script. After that, we saw a nice decreasing trend in Redis memory usage:

We did not scan the full database on the first run just to make sure that there were no problems with updating TTLs. After we were sure that everything was without any issues, we ran it on the rest of the database:
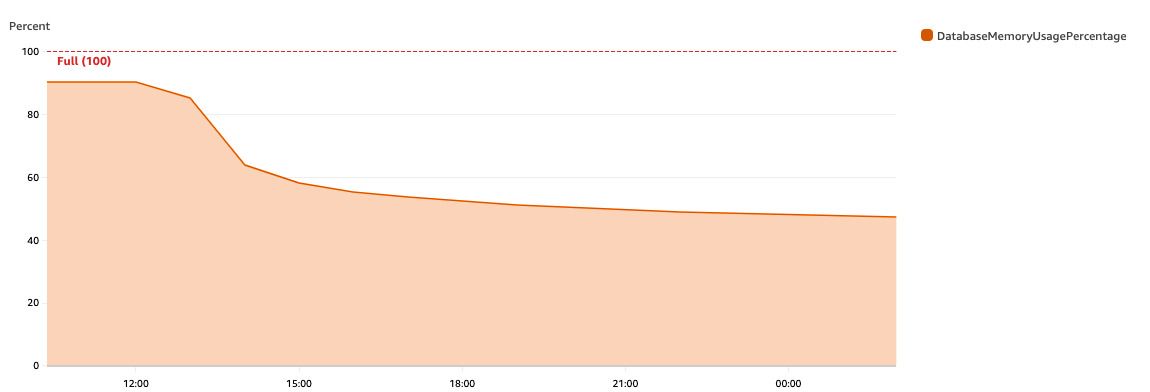
We expected a sudden decrease in the number of items in Redis in one hour after the script finished. However, we saw that the database usage decrease spans over multiple hours during the day. It is related to how Redis cleans up expired items.
Expiring Items
Redis provides two ways to remove items: active and passive. In this article, we’ll focus on the passive approach.
The passive way involves Redis periodically checking 20 random keys from the set of keys with an associated expiration. If any of these keys have expired, Redis deletes them. If more than 25% of the keys have expired, Redis repeats the process until less than 25% of the keys have expired. This gradual deletion process explains why there may not be a sharp decrease in memory usage after setting the correct TTLs. Redis takes some time to remove expired items at its own pace. More on that in Redis docs.
If you attempt to retrieve an expired item from Redis before it’s removed by this cleanup process, it will be deleted, and you won’t receive the item. This is known as the active way of expiring items in Redis.
The Big Reveal
Earlier, I promised to tell you the cause of all of this that we figured out. So, here it goes… It was all caused by an integer overflow.
The app is written in Golang, and the call to Redis to add an item with a TTL accepts a parameter of type time.Duration. Previously, in our application YAML config, we used to store the ticket expiration as a number of seconds. Later, we refactored the app and made a change to store that config value in nanoseconds. However, we forgot to update the part of the code where seconds were converted to nanoseconds. So, eventually, we have code that multiplies nanoseconds by 10^9, which overflows an integer and it becomes negative.
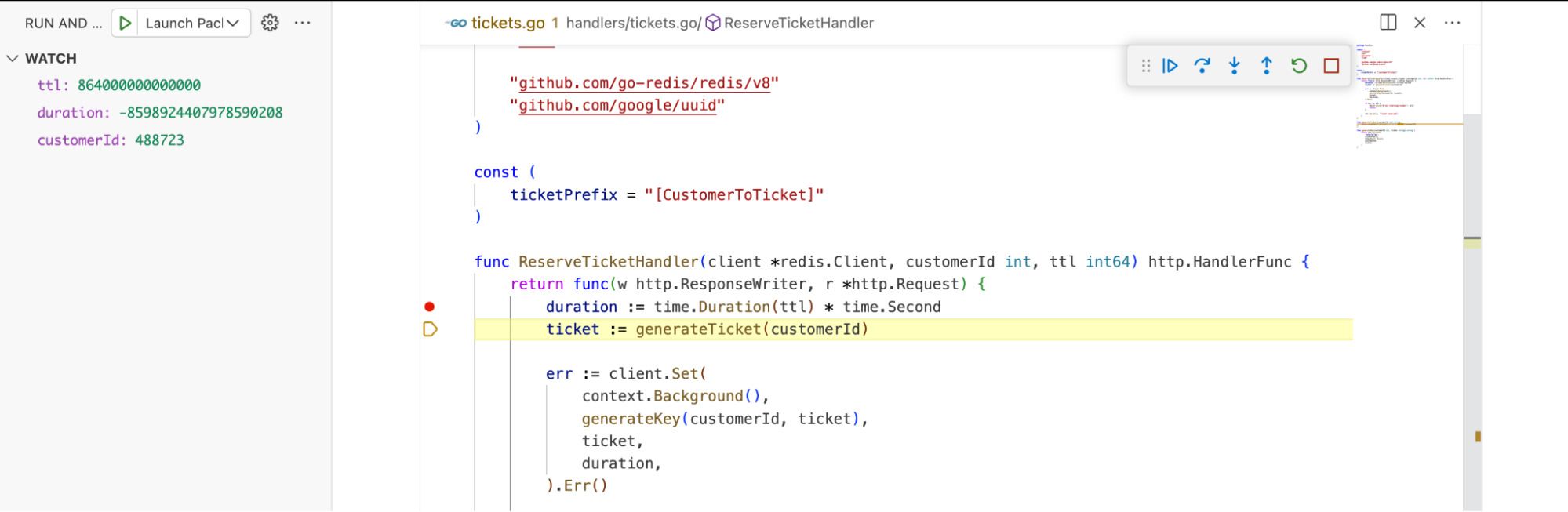
At least in the Golang Redis client, a negative TTL means no TTL, which means that we have been inserting all items without a TTL into Redis since this bug was introduced. We discovered this bug by simply running the app code locally and going through the data insertion process to Redis with a debugger. This was an easy fix – we removed the unnecessary multiplication, and all new items now had a proper TTL set. Of course, finally, we updated our test cases so that this would never happen again.
200 – OK
After running our script to clean up the database, we were delighted to see the memory usage drop to a healthy ~50%. As we deployed the fix for our application, we no longer had to worry about a never-ending surge of items, and the number started to fluctuate throughout the day – just as it should. The old tickets were expiring and getting removed, while the new ones were issued and added to Redis. All’s well that ends well, and everyone lived happily ever after.
Alright, so what can we take away from this imaginary story?
- Know your Redis eviction strategy well. It is useful to know what will happen with your data if Redis runs out of memory for any reason.
- Know the number of items in Redis with and without TTL – info command can tell that.
- Monitor your database memory usage and have alerts set up based on that.
- Having Redis backups may sound unnecessary if you are using Redis for cache only and not storing any important data. However, they are still useful since they could be downloaded and used as a tool to inspect your cache without accessing production clusters.
- If an item in Redis has expired – it might not be deleted immediately. It will be deleted eventually once the Redis cleanup process reaches it.
Getting back to reality. While human mistakes are inevitable, it is important to note that we should strive to prevent critical ones. Those horror stories in Software engineering (or DevOps) are the best learning opportunities when you manage to catch them just before they become critical. Hope this story will serve as a learning opportunity for you as well.
Like what you see? Share with your team.
Published 16/04/2024

Tomas Bareikis
Software Engineer

blog
Redis: The Memory Usage Mystery
